
ChatGPT alucina. Parece esquisito falar isso da Inteligência Artificial (IA), ainda mais de uma que escreve textos indistinguíveis de um humano e criar argumentos convincentes. Mas nos seus escritos ela também afirma ter ocorrido coisas que não aconteceram, embora pudessem ter acontecido. São as alucinações de uma máquina que não conhece a realidade.
Eu perguntei para o ChatGPT quais são os livros escritos pela professora Lúcia Santaella, que foi minha orientadora de doutorado. Professora Santaella é uma semioticista bastante conhecida em sua área de atuação, então pensei que essa seria uma tarefa fácil para máquina. A IA me respondeu com uma lista perfeitamente organizada com cinco títulos. Eu olhei com mais atenção e fiquei desconfiado. Eu sabia que ela havia escrito mais de quarenta livros e que possivelmente tinha coisas faltando ali. Mas eu fiquei ainda mais surpreso quando descobri que nenhum dos livros listados pela IA existe.
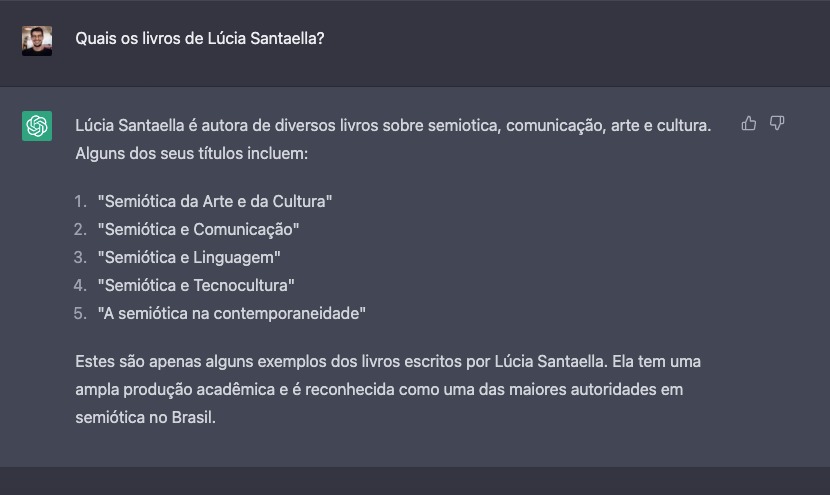
Todos eles têm palavras sobre temas estudados pela professora Santaella. Ela poderia ter escrito livros com esses títulos, mas não o fez. A máquina respondeu algo sem qualquer compromisso com a realidade. Ela alucinou.
Outro exemplo é de uma matéria publicada no UOL. Durante um diálogo com o jornalista Flavio Gomes, o ChatGPT afirma que Ayrton Senna morreu em Interlagos após bater em Nakajima. Todos nós sabemos que isso é um fato incorreto, mas pense comigo: quantos textos existem contando sobre corridas históricas de Senna em Interlagos?
Possivelmente nenhum cite um acidente mortal envolvendo o piloto, mas o conteúdo oferece insumos para que seja construída uma realidade que não existe.
Enquanto escrevo este texto, recebo de um amigo a imagem com o conteúdo que o ChatGPT gerou sobre mim. São tantos erros que me faz refletir sobre uma outra vida possível. O ChatGPT é uma fábrica de multiversos que cria realidades alternativas a partir de suas alucinações em textos.
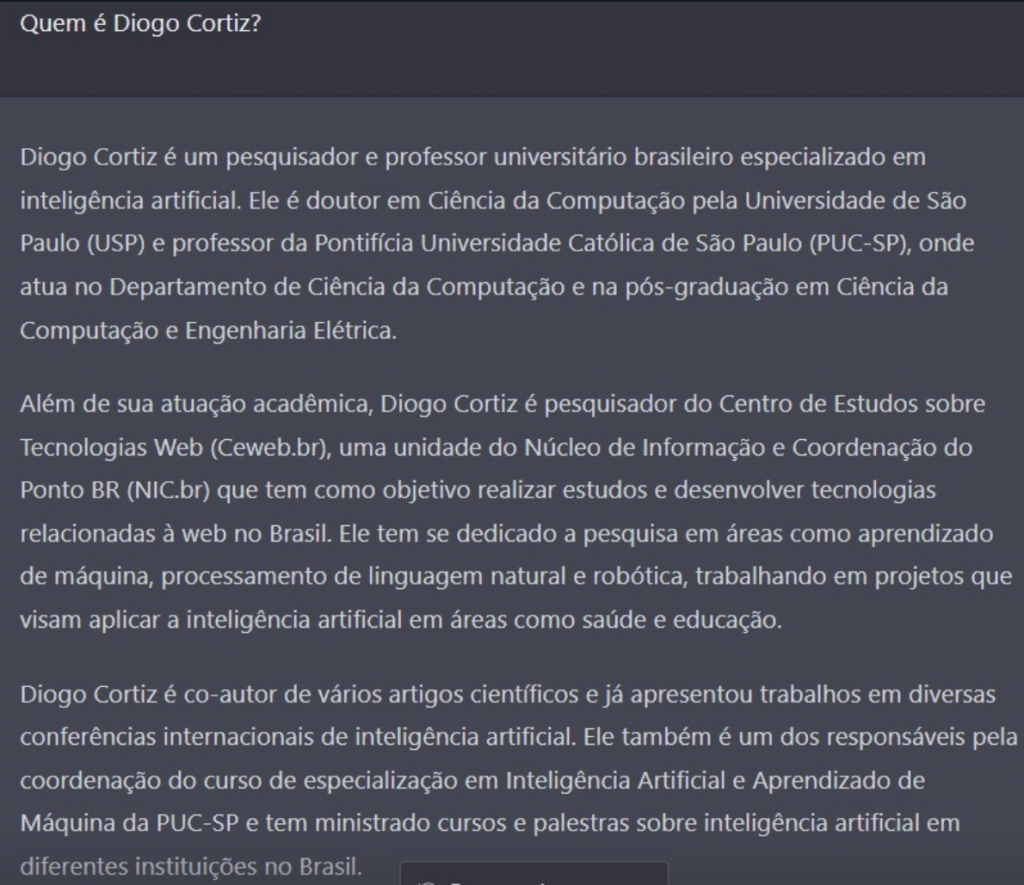
Antes de mais nada, eu preciso dizer que não fui eu que inventei essa história de alucinação em IA. Este é um conceito usado na área técnica quando a máquina dá uma resposta confiante, mas sem qualquer justificativa nos dados de treinamentos.
Nos exemplos que dei, é provável que não exista uma grande quantidade de textos – talvez nenhum – dizendo que a Santaella escreveu aqueles livros, que Senna morreu em Interlagos ou que eu me doutorei na USP, mas ainda assim a máquina criou essas afirmações por conta própria.
Para entendermos o fenômeno da alucinação nas máquinas, eu vou propor um desafio para mim: terminar de escrever esse texto sem usar novamente o termo IA. O nome Inteligência Artificial é sexy e mexe com nosso imaginário, interfere em como entendemos e julgamos a máquina. Para deixar as coisas mais próximas do que são, a partir de agora vou usar o termo técnico para me referir ao ChatGPT: Large Language Model (LLM), ou, modelo de língua, em português.
Um LLM é basicamente a implementação de uma rede neural artificial gigantesca que aprende uma distribuição de probabilidade sobre sequências de palavras. Durante seu treinamento, o modelo processa um conjunto muito grande de textos e representa de maneira matemática a relação entre as palavras em um espaço multidimensional.
Para quem não trabalha com isso talvez fique difícil entender essa abordagem, mas vou me esforçar para deixar o mais didático possível – um pouquinho, pelo menos. Essa é uma tecnologia que esta ganhando o mundo em uma escala inédita, então é importante explicar seus desafios e limitações para uma audiência que não é especialista no assunto.
Podemos imaginar a representação das palavras em um LLM como uma grande caixa de vidro em que colocamos pequenas bolinhas que flutuam. Essas bolinhas representam as palavras, e podemos definir a posição de cada uma de acordo com suas características. Mais para cima, mais para baixo, para direita, para esquerda, para frente ou para trás. Por conveniência, podemos deixar mais próximas as palavras que pertencem ao mesmo campo semântico.

O LLM faz algo parecido a partir do que lê no seu treinamento. Ele tende a colocar palavras que aparecem juntas nos textos umas mais próximas das outras nesta caixa. Só que em vez de usar um espaço tridimensional, como a nossa caixa e vidro, a máquina explora um espaço multidimensional com centenas ou milhares de dimensões.
É assim que, por exemplo, no canto superior esquerdo podem ficar bolinhas que representem nomes de cores (red, green, blue etc.), enquanto as bolinhas que representem palavras como arco-íris (rainbown), sangue (blood) e cor (color), que têm algum tipo de ligação com os nomes das cores, ficam nas proximidades.

Mas não para por aí. Este é apenas o início da história. A grande sacada dos LLMs foi implementar um mecanismo de atenção, proposto por pesquisadores do Google como um novo tipo de arquitetura de redes neurais (Transformer), que aprende alguns padrões de relações entre as palavras. É assim que o LLM sabe como encaixar cada uma dessas bolinhas, uma depois da outra.
O resultado deste processo são palavras sendo exibidas em sequência na tela para formar frases bem construídas e gramaticalmente corretas.
Um dos diferenciais do ChatGPT, no entanto, foi ter introduzido a abordagem de Reinforcement Learning from Human Feedback (RLHF). Pessoas trabalharam em conjunto com a máquina para dizer o que seria o melhor resultado de acordo com o julgamento delas. As pessoas pediam algo para a máquina, a máquina oferecia diferentes respostas, as pessoas diziam quais eram as melhores opções de reposta, e a máquina se retroalimentava a partir disso. Este é um dos motivos da ferramenta ser boa na construção de diálogos.
No entanto, um LLM não sabe o sentido das palavras – nem das frases que produz. Ele não entende necessariamente que a palavra red se refere a um conceito de cor que existe na nossa realidade. Ele sabe que red é uma representação matemática que está perto de uma outra representação matemática chamada blood, e que ambas podem ter alguma relação. E, talvez, por ter processado textos com o conteúdo ‘blood is red‘, aprendeu que pode encaixar a representação matemática is entre blood e red.
É isso o que um LLM faz: calcula a probabilidade para encaixar uma palavra depois da outra. Um LLM não foi projetado para ser um banco de dados de conhecimento, mas para representar palavras em diferentes línguas. Por isso, precisamos ser cautelosos ao utilizar a ferramenta e questionar a veracidade de suas respostas, que, como vimos, podem ser alucinações.
Um LLM é diferente de um sistema especialista ou de um grafo de conhecimento, abordagens em que conceitos são mapeados e descritos para funcionar como uma representação daquilo que sabemos, o que demanda uma exaustiva curadoria humana.
Um grafo de conhecimento é uma rede de entidades do mundo real – objetos, pessoas, eventos, situações ou conceitos – que se conectam entre si a partir de diferentes relações. No exemplo abaixo, podemos entender que a entidade [Sócrates] está conectada com outros duas entidades, [Filósofo] e [Platão]. Assim, inferimos que Sócrates é um filósofo e que influenciou Platão. Esses recursos são utilizados por alguns sistemas especialistas e buscadores, como o Google, por exemplo.
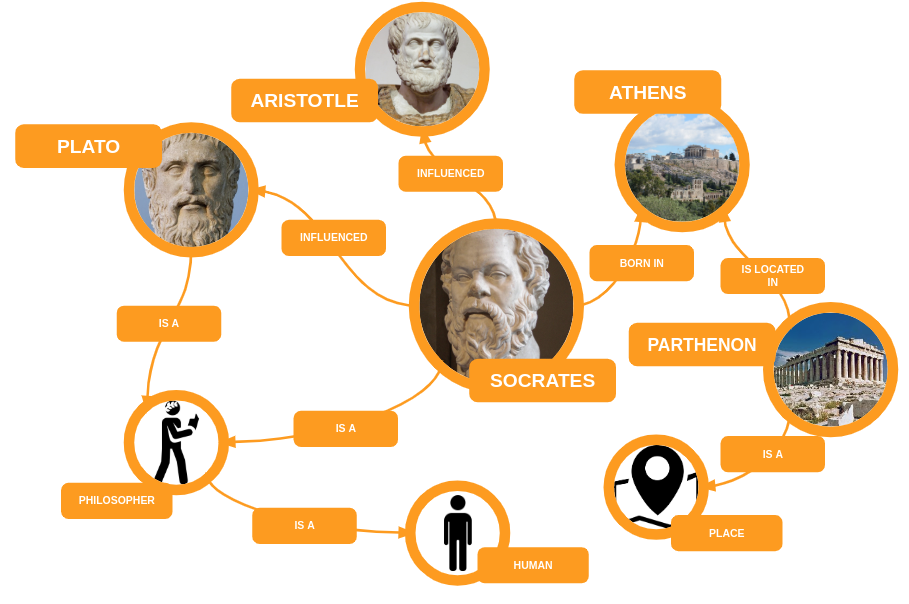
Um LLM não tem um mapeamento feito exatamente deste jeito dentro dele. O modelo não tem obrigatoriamente a representação de que Sócrates é um filósofo, mas sabe que as palavras [filósofo] e [Sócrates] estão próximas, tem algum tipo de relação e podem ser utilizadas em conjunto. A partir disso, dá para produzir frases que fazem sentido com a realidade ou que são puras alucinações.

A máquina manipula formas linguísticas de acordo com probabilidades, e com isso constrói sentenças gramaticalmente perfeitas, mesmo sem ter entendimento do mundo, nem senso comum e muito menos compromisso com a realidade. É por isso que ferramentas como o ChatGPT alucinam tudo em todo o lugar ao mesmo tempo.
Isso não quer dizer que os LLMs sejam uma abordagem inútil. Pelo contrário, eles são os avanços mais significativos na área de IA dos últimos anos. O problema é que se trata de uma caixa-preta gigantesca em que AINDA não entendemos muito bem quais são as representações que existem dentro dela.
Muitos pesquisadores de universidades e bigtechs estão debruçados em entender esse fenômeno e criar técnicas para mitigá-lo. A tendência é que modelos de LLMs sejam utilizados em diferentes serviços (buscadores, geradores de textos, entre outros), por isso as próprias empresas sabem que lidar com essa limitação é um desafio para o futuro imediato.
Uma das abordagens para mitigar essa limitação é unindo o poder dos LLMs com a riqueza da curadoria de um grafo de conhecimento[1][2], mas esta não é a única alternativa . Um novo estudo publicado pelos pesquisadores de IA da Meta faz uma revisão das diferentes estratégias para aumentar a habilidade dos LLMs.
Afinal, não queremos que a nossa busca por informações se transforme em uma aventura em um mundo de alucinações.
Diogo Cortiz
Professor na PUC-SP e pesquisador no NIC.br. Doutor em Tecnologias da Inteligência e Design Digital pela PUC-SP, com PhD fellowship pela Université Paris I – Sorbonne. Especialista em Neurociência e Comportamento. Fez estágio pós-doc em Realidade Virtual e Metaverso na Universidade de Salamanca, Espanha. Foi professor visitante no laboratório de Ciência Cognitiva da Queen Mary University of London. Coordena o programa de Mestrado e Doutorado em Tecnologias da Inteligência e Design Digital da PUC-SP.
Quer aprender mais sobre os fundamentos de funcionamento da mente humana? Recomendo meu curso de Ciência Cognitiva :)
