
Inteligência Artificial e Privacidade são os dois assuntos que certamente estão guiando muitas discussões na área de tecnologia. O curioso é que em um primeiro momento parecem coisas antagonistas, até mesmo para quem trabalha com elas. Talvez seja um efeito da própria natureza de suas aplicações ou dos debates que acontecem de forma isoladas entre as áreas. Talvez os dois. De um modo geral, enquanto a turma de IA demanda uma quantidade absurda de dados para treinar seus modelos, a turma da privacidade está preocupada em restringir o acesso para garantir a intimidade dos usuários. Errados não estão. Nem um nem o outro.
A IA evolui quando três principais componentes são combinados: aumento da capacidade computacional, incremento da quantidade de dados disponíveis e, é claro, desenvolvimento de novas abordagens e arquiteturas de modelos. Mas entre todos, os dados ainda são os combustíveis essenciais. Ainda que eu tenha à minha disposição o melhor servidor e os algoritmos estado da arte, pouco consigo fazer se não tiver dados disponíveis para treinar o meu modelo. E digo isso por experiência própria. Desde o início do ano estou trabalhando como professor visitante na Queen Mary University of London, em uma pesquisa sobre detecção de discurso de ódio. Neste projeto estamos trabalhamos com o que chamamos de ‘aprendizado supervisionado’, ou seja, a máquina aprende o que é considerado ‘discurso de ódio’ a partir de exemplos, o que requer uma grande coleção de sentenças (frases coletadas do twitter, por exemplo) anotadas por pelo menos três profissionais cada. As pessoas devem ler as frases e marcar se ali contém discurso de ódio ou não (o que é entendido como discurso de ódio ficará para outro post).
O meu problema é que temos poucos datasets deste tipo para a língua portuguesa. Enquanto meus colegas estão trabalhando com um conjunto de 50 a 100 mil sentenças em inglês, eu tenho que me virar com um de 5 mil em português. Esse é apenas um exemplo de uma situação se repete em muitas outras áreas, com em projetos para a saúde, agricultura, mercado financeiro, entre outros. Modelos mais robustos demandam mais dados, e quanto mais detalhes (granularidade) nos dados, melhor.
Agora que vimos a importância dos dados para a IA, podemos convidar ao palco outro personagem, com sua narrativa também plausível, a Sra. Privacidade, que traz muitos questionamentos. Tudo bem que devemos melhorar nosso modelos de IA, mas a qual custo? como fica a intimidade de todos os usuários de um serviço? devemos então proibir o compartilhamento de todos os dados para treinamentos de IA? Ainda que seja dados da área da saúde que possam levar a um sistema melhor e mais barato de diagnóstico? essa é uma troca razoável para as sociedades?
Qualquer resposta simples para todas essas perguntas complexas é uma alternativa inocente. Não existe uma receita pronta, mas pelo menos está começando esforços na indústria e academia para juntar as duas áreas. Muita gente me perguntou nos últimos meses, até por causa do Workshop FATES, o qual sou um dos organizadores, se é possível compartilhar dados para treinamento de modelos de IA ao mesmo tempo que se garanta níveis de privacidade das pessoas. Ainda não temos uma resposta definitiva, mas alguns caminhos estão sendo abertos neste sentido. E é isso que compartilharei com vocês. Nesta série, dividida em dois ou três episódios, vou apresentar o estado da arte de abordagens e técnicas que estão sendo desenvolvidas para buscar anonimizar dados e garantir a privacidade.
E nesse primeiro capítulo começarei do início. Não do gênesis da privacidade, mas a partir de um dos estudos mais conhecidos sobre privacidade em dados. Em 1997, a pesquisadora Latanya Sweeney, aluna de doutorado no MIT, publicou um estudo para mostrar que a anonimização dos dados é um processo complexo e que nem sempre garante a não reidentificação de pessoas em um conjunto de dados anonimizado.
Ela foi motivada por uma iniciativa do estado de Massachusetts para liberar registros médicos que fossem utilizados na área de pesquisa. O governador William Weld garantiu que a base de dados tinha passado por um processo de anonimização, e que portanto a privacidade dos pacientes estava assegurada. De fato, o órgão responsável removeu dados que pudessem identificar o registro das pessoas, como nome, endereço e número da seguridade social, mas manteve o CEP, data de nascimento e sexo — dados que poderiam ser importantes para as pesquisas.
Latanya Sweeney, que não estava totalmente convencida, decidiu fazer um experimento para estudar se, por meio de um cruzamento com outras bases, conseguiria reidentificar as pessoas. E foi ainda mais ousada: queria encontrar os registros do próprio governador. Ela comprou uma base com dados eleitorais da cidade de Cambridge, capital do estado, com o nome, data de nascimento, sexo, endereço e CEP de todos os votantes.
Com os dados em mãos, a tarefa ficou fácil. Ela logo identificou que apenas seis pessoas na cidade tinham a mesma data de nascimento do governador. Destes seis, apenas três eram homens. Dos três, apenas um morava no mesmo CEP do governador. Latanya acabou enviando a ficha médica do governador para o seu escritório, e assim abriu uma boa discussão sobre o processo de anonimização de dados.
Mas esse não é o único caso. Em 2006, uma situação similar se repetiu, agora com uma empresa privada. A Netflix, que na época era a maior empresa online de aluguel de filmes, criou o “Netflix Prize”, uma competição que visava melhorar os seus algoritmos de recomendação. Para isso, a empresa liberou um dataset com dados sobre a avaliação dos filmes pelos usuários. Basicamente, cada filme continha dados sobre data e hora de cada usuário para cada filme. Para respeitar a privacidade, a companhia anonimizou os dados antes de liberá-los aos participantes. No entanto, pesquisadores conseguiram reidentificar boa parte dos usuários cruzando a base de dados da Netflix com os registros de avaliação no site IMDB.
As duas situações descritas acima ajudam no entendimento de que anonimizar os dados é mais complexo do que apenas remover identificadores únicos, até porque existem quasi-identifiers (quase identificadores) na maioria dos datasets, atributos que sozinhos não são identificadores únicos, mas que criam um identificador único quando combinados com outros quasi-identifiers. Por exemplo, a união da data de nascimento, sexo e CEP pode ajudar a identificar uma pessoa ou então funcionar como proxy para outras inferências — descobrir a etnia, por exemplo.
Eu vou aproveitar este momento para apresentar um primeiro conceito mais técnico desta nossa série, chamado K-anonymity, uma propriedade que um conjunto de dados apresenta de acordo com o seu nível de anonimização. Proposto pela Latanya Sweeney e Pierangela Samarati, a técnica nos ajuda a identificar se um determinado estado do datasets apresenta ‘garantias’ de que os indivíduos não sejam identificado, ao mesmo tempo que o conjunto de dados continuem úteis. Dizemos que uma base de dados é 2-anonymity, por exemplo, quando a combinação de seus atributos não puderem ser distinguíveis de pelo menos 2 indivíduos.
Preparei uma situação ilustrativa para deixar a explicação ainda mais clara. Imagine que o ‘Hospital A’ liberou o dataset abaixo (os nome dos pacientes são meramente ilustrativos). Neste caso, Horácio, o estagiário, simplesmente exportou uma tabela diretamente do sistema de prontuário eletrônico.

Como vocês podem perceber, este dataset não apresenta nenhum tipo de anonimização. O nome é um identificador único. O diretor do hospital, Sr. Gregory, preocupado com o escândalo que a situação pudesse causar, imediatamente ordenou que Horácio anonimizasse o conjunto de dados antes de liberar o acesso ao pesquisadores.
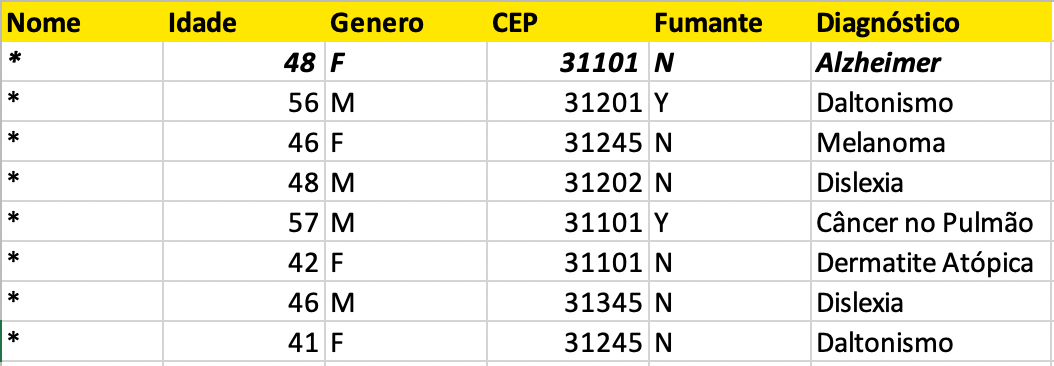
A solução encontrada por Horácio foi a mais simples: removeu todos os identificadores únicos, que neste exemplo era apenas o nome. O estagiário achou que agora os dados estavam anonimizados, já que não existia nenhum identificador único no dataset. O problema é que Horácio não conhecia o conceito de quasi-identifiers, mas você que já conhece pode sacar o risco. Se a minha amiga de 48 anos, moradora no CEP 31101, não fumante, está internada no ‘Hospital A’, eu posso facilmente identificá-la no conjunto de dados, descobrindo inclusive que ela tem Alzheimer, um dado sensível.
Para melhorar as questões de privacidade, eu posso aplicar algoritmos de K-anonymity para evitar a reidentificação dos pacientes. Hoje existem diferentes técnicas e algoritmos para este fim, mas a maioria utiliza dois métodos principais:
- Supressão: quando alguma informação é removida do conjunto de dados.
- Generalização (coarse): quando substituímos um valor único por uma categoria mais ampla ou um intervalo de valor
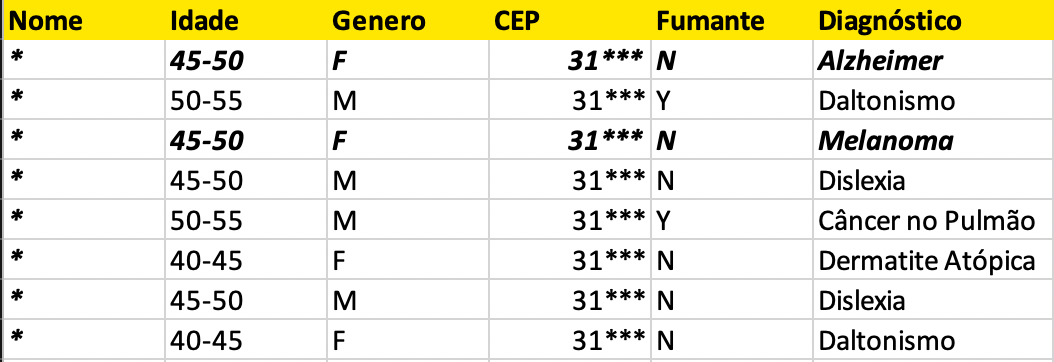
Neste exemplo, o Horácio utilizou o método de supressão para o atributo ‘Nome’ e generalização para o atributo ‘CEP’ para disponibilizar um dataset 2-anonymity. Agora não importa o quanto uma pessoa combine os atributos, sempre chegará em pelo menos dois registros. A reidentificação direta já não é possível, então isso quer dizer que a anonimização está garantida?
Há um debate intenso sobre isso, até porque há opiniões divergentes na área técnica, jurídica e filosófica. Eu não sou nenhum especialista em leis de proteção de dados — pelo contrário -, mas a minha posição é que neste caso a anonimização não garante a privacidade. Mesmo que eu não consiga reidentificar a pessoa, eu ainda tenho uma violação da privacidade. Se eu sei que minha amiga de 48 anos, não fumante e que mora no distrito X (cujo o CEP começa com 31**) foi internada no ‘Hospital A’, eu consigo descobrir que seu diagnóstico é Alzheimer ou Melanoma.
E esse cenário pode piorar se eu combinar mais um conjunto de dados. Imagine que o ‘Hospital B’ também disponibilize um dataset para ajudar os pesquisadores. Mas neste caso a equipe de TI foi mais prudente e publicou a primeira versão do conjunto de dados com a propriedade 2-anonymity.

O cruzamento de dados dos dois hospitais permite a reidentificação da pessoa. Se minha amiga de 48 anos, não fumante e que mora no distrito X (cujo o CEP começa com 31**) foi diagnosticada com Alzheimer ou Melanoma no ‘Hospital A’, eu consigo inferir qual é o exato diagnóstico ao cruzar seus registros com os dados publicados pelo ‘Hospital B’. Ficou fácil descobrir que Meredith tem Alzheimer. Como? este é o único diagnóstico comum nos dois conjuntos de dados para os mesmos atributos.
Certamente este cenário é bastante simplista e descolado da realidade, mas a ideia é que seja fácil para ilustrar e deixar o conteúdo mais didático, algo mandatório para um texto introdutório. O fato é que privacidade em IA não é tão trivial. Neste caso, mesmo com ambos os datasets respeitando a propriedade 2-anonymity, não é possível garantir a anonimização. Existem novas abordagens que buscam aumentar critérios de privacidade sem que degrade muito a acurácia do modelo. Mas esta é uma questão sensível, porque invariavelmente teremos um trade-off entre o nível de privacidade e o desempenho do modelo. Podemos aumentar a privacidade removendo informação ou adicionando ruído ao conjunto de dados, e em ambos os casos haverá um impacto na acurácia do modelo.
O importante é encontrar um equilíbrio entre os dois critérios (o que também acontece na questão de fairness). A área de Differential Privacy, que inclusive foi listada na MIT Technology Review como uma das 10 tecnologias mais promissoras para 2020, é uma das que se ocupa com esta questão. Iremos discutir mais sobre isso nos próximos capítulos.
Este é o primeiro texto de uma pequena série que irei abordar sobre a importância da privacidade em projetos de IA. Também gravei o vídeo abaixo para resumir a explicação. Fique antenado nas próximas publicações e não esqueça de comentar, mandar sugestões e se inscrever no canal do Youtube.